Overview
This is a demo for deploying Composer AI.
Composer AI is Red Hat’s cutting-edge platform for rapidly developing and deploying generative AI solutions that transform enterprise workflows. Designed to integrate seamlessly with Red Hat OpenShift, Composer AI enables users to create AI assistants tailored to specific business needs, leveraging technologies like LangChain4J, Vector Databases, and GraphRAG. These assistants enhance productivity by automating tasks such as summarization, data retrieval, project management, and decision support. Composer AI simplifies the deployment process while providing robust support for hybrid cloud environments, and a focus on scalability and security, Composer AI empowers organizations to streamline operations, solve complex problems, and innovate at scale—all while leveraging Red Hat’s trusted infrastructure.
This environment includes the following components for composer:
- The Composer UI - Pattern Fly Frontend
- The Conductor API - Quarkus/Langchain4J API
- LLM Instance - Granite modes running on vLLM Serving Runtime
- Vector Database - Elastic Search DB
- Ingestion Pipelines - Series of KFP Pipelines ingesting Red Hat Documentation
Environment Information
All of the components relevant to Composer AI are located in the composer-ai-apps namespace, and can be viewed inside the Develolper -> Topology view
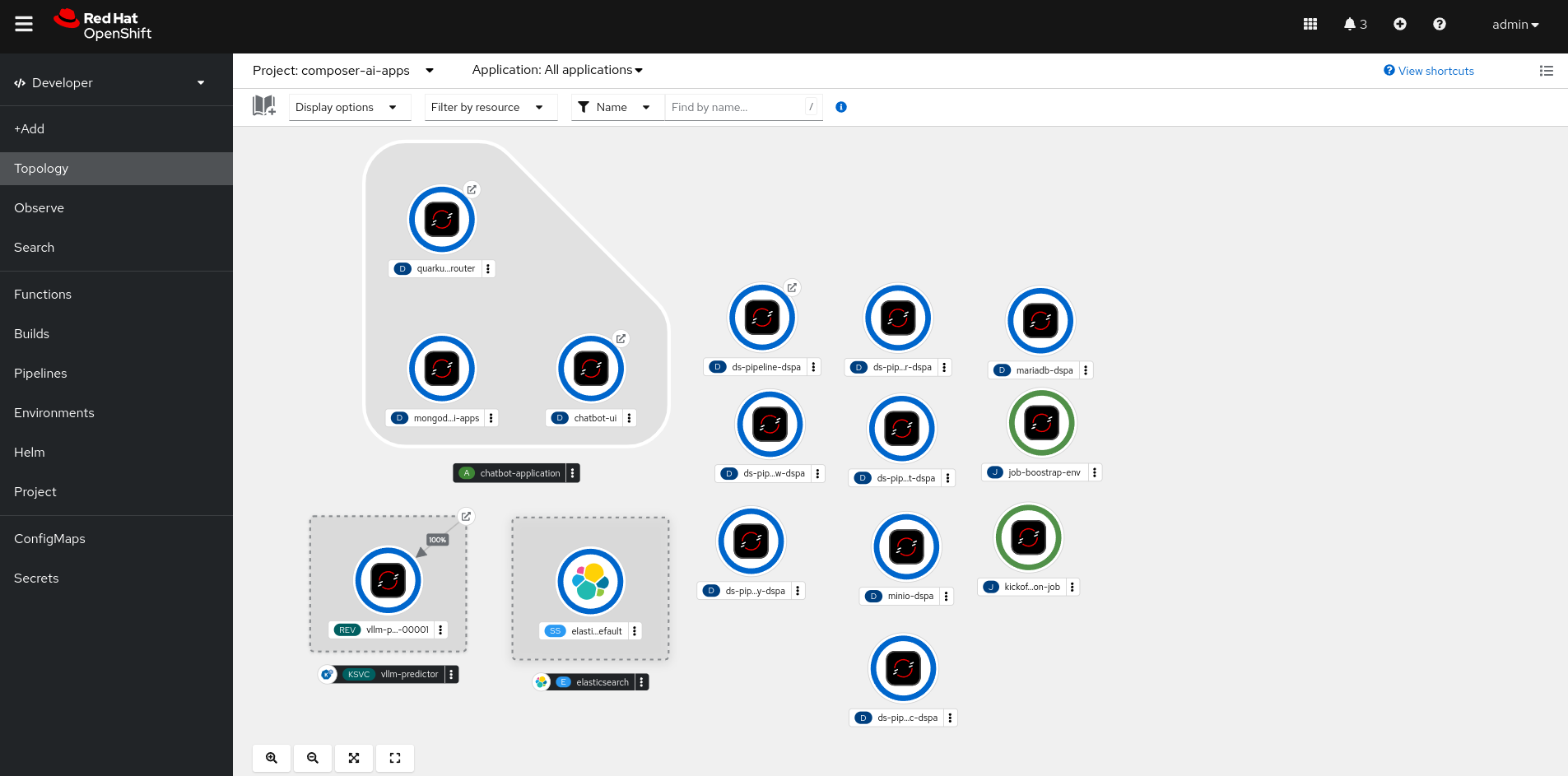
The Cluster Level and Composer Level Gitops used to deploy the application can be accessed through the “waffle” button on the top right.
And the endpoint for the UI can be found on either the Topology view or Networking -> Routes
Environment Validation Instructions
Estimated Setup Time: Approximately 30 minutes
Before you begin: Please allow up to 30 minutes after the cluster becomes available for the Composer AI demo environment to be fully operational. The UI and API will be available sooner, but the assistants will not be ready until ingestion is complete.
Warning
Please read the following section to validate the environment has come up before reporting issues.
LLM Validation
- Navigate to the
composer-ai-namespace,Serverless -> Serving. - Verify the Knative service is running (see images below).
Success:
 Failed/Pending
Failed/Pending

Tip
If the LLM is down, check
Conditionssection under theDetailstab of the Knative Service for more debugging information
- Once the LLM is running, the
Default/Meeting Minute/Email Summary/Email Draft Assistantsshould be functional. Other assistants will be available after ingestion is complete
Ingestion Validation
-
The ingestion pipeline usually takes about 30 minutes to complete after the cluster is up.
-
A job on the cluster will wait for all the required resources to be created and then kick off the
ingestion-pipelineTekton Pipeline. -
Monitor the
ingestion-pipelineby navigating toPipelines -> Pipelines -
Once complete this will kick of a KFP pipeline
-
To track ingestion progress:
- Open the Red Hat Openshift AI UI (waffle button at the top).
- Go to
Experiments -> Experiments and runs -> document_ingestion. - Ensure all tasks have completed successfully.
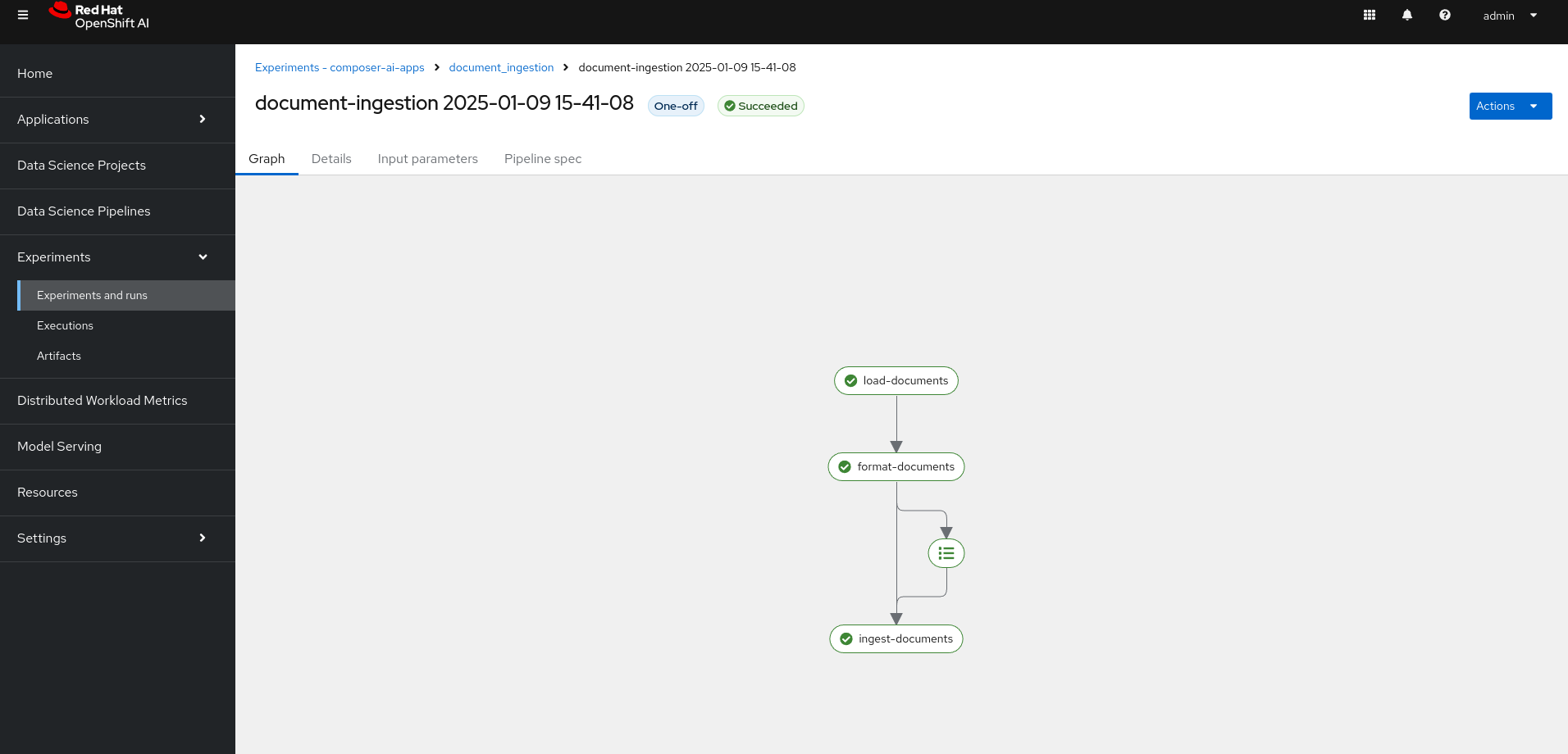
Tip: If the pipeline encounters a connection issue, restart it from the Pipelines view on Openshift using the
Start Last Runoption.